Running Spark Rapids on OpenShift
The following post is to summarize a proof of concept I conducted with Erwan Gallen for deploying Apache Spark clusters on OpenShift Cloud Platform, using GPU support provided by the Spark Rapids Spark Plugin. The OpenShift objects and other artifacts referenced here can also be found at this github repo.
Background
The Spark Rapids plugin leverages the ability of Apache Spark to discover and load jar files that customize certain aspects of Spark’s behavior. In the case of Spark Rapids, the plugin enhances Spark’s Catalyst query planner so it can automatically detect Spark operations that can be accelerated by GPU hardware and route them to available GPUs.
Container Images for Spark Rapids
To run on a container orchestration platform such as OpenShift or its upstream Kubernetes, we must begin by creating a container image with Spark, CUDA, and Spark Rapids installed. CUDA can be obtained pre-packaged from one of the nvidia CUDA images. In this POC, we used a CUDA 10.x based on ubuntu. More recent versions of CUDA are now also available installed on top of Red Hat UBI.
You can refer to the Dockerfile we created on this POC for examples of how to install the Spark, Spark Rapids and GPU dependnecies.
Additionally, you must install GPU drivers appropriate for your hardware platform onto your image.
As you can see
in the Dockerfile,
one can install a selection of GPU drivers directly from the ubuntu package manager:
in our study we installed nvidia-driver-440.
You can also
download drivers
directly to install them on your image.
Lastly, note that Spark typically uses a special
entrypoint
script that pre-configures an entry in the /etc/passwd file that Spark requires to start up.
The particular images we built for this study are available here.
Deploying on a Cluster
For our proof of concept, we ran spark-shell on a pod from inside the cluster.
In order for our spark-shell command to successfully operate inside the cluster,
we need to deploy some supporting Kubernetes objects.
Each item links to the corresponding YAML file on the project repository.
- a spark service account to provide permissions for the spark kubernetes scheduler to create executor pods.
- a role-binding that assigns the service account permissions to create pods. Creating the rolebinding in this example requires administrator permissions.
- a headless service that allows spark’s executors to connect back to the driver pod.
- a service and route that expose Spark’s web UI
With these objects installed, we can now set up a pod for our spark-shell run.
The run command looked like this example, which provides a remote shell on the cluster pod
at our command line:
$ oc run -i -t --serviceaccount=spark spark --image=quay.io/erikerlandson/spark-rapids:latest --command -- /bin/bash
In the next section we will describe the configuration arguments for enabling a spark-shell with
Spark Rapids GPU support.
Configuring Spark to use Rapids
We ran spark-shell from the command line of our pod, as created in the oc run command above.
The following command details all the configuration arguments needed for Spark to connect
to the in-cluster kubernetes API, set Spark’s resource requirements, instruct Spark to use
GPUs for its tasks and enable Spark Rapids:
$ ${SPARK_HOME}/bin/spark-shell --master k8s://https://kubernetes.default:443 \
--conf spark.kubernetes.authenticate.submission.oauthToken=$(cat /run/secrets/kubernetes.io/serviceaccount/token) \
--conf spark.kubernetes.container.image=quay.io/erikerlandson/spark-rapids:latest \
--conf spark.driver.host=$(hostname) \
--conf spark.locality.wait=0s \
--conf spark.driver.memory=2g --conf spark.executor.memory=4g \
--conf spark.executor.cores=1 --conf spark.task.cpus=1 \
--conf spark.plugins=com.nvidia.spark.SQLPlugin \
--conf spark.executor.resource.gpu.discoveryScript=/opt/getGpusResources.sh \
--conf spark.executor.resource.gpu.vendor=nvidia.com \
--conf spark.rapids.sql.concurrentGpuTasks=1 \
--conf spark.rapids.memory.pinnedPool.size=1g \
--conf spark.task.resource.gpu.amount=1 \
--conf spark.executor.resource.gpu.amount=1 \
--conf spark.worker.resource.gpu.amount=1 \
--conf spark.sql.files.maxPartitionBytes=512m \
--conf spark.sql.shuffle.partitions=10
The following arguments tell Spark how to connect its driver (spark-shell) to the kubernetes API and use the service account we set up for our shell pod:
--master k8s://https://kubernetes.default:443
--conf spark.kubernetes.authenticate.submission.oauthToken=$(cat /run/secrets/kubernetes.io/serviceaccount/token)
The spark.driver.host configuration tells spark to advertise its driver location as the in-cluster address of the pod it’s running on:
--conf spark.driver.host=$(hostname)
These configurations tell spark how to discover GPU driver information on the physical machines its pods are running on, and to use GPU support for its tasks:
--conf spark.executor.resource.gpu.discoveryScript=/opt/getGpusResources.sh
--conf spark.executor.resource.gpu.vendor=nvidia.com
--conf spark.task.resource.gpu.amount=1
--conf spark.executor.resource.gpu.amount=1
--conf spark.worker.resource.gpu.amount=1
Lastly, these configurations specifically instruct Spark to use the Spark Rapids plugins:
--conf spark.plugins=com.nvidia.spark.SQLPlugin
--conf spark.rapids.sql.concurrentGpuTasks=1
--conf spark.rapids.memory.pinnedPool.size=1g
Demonstrating Spark Rapids
Once we have started up our spark-shell as detailed above,
we can run a test to demonstrate the Spark Rapids is accelerating our Spark operations.
The following session runs a simple join operation and then examines the corresponding query plan
using the Spark SQL explain operator to verify that Spark Rapids is operating on the query:
scala> val dfa = sc.makeRDD(1 to 10000000, 6).toDF("a")
dfa: org.apache.spark.sql.DataFrame = [a: int]
scala> val dfb = sc.makeRDD(1 to 10000000, 6).toDF("b")
dfb: org.apache.spark.sql.DataFrame = [b: int]
scala> dfa.registerTempTable("tba")
scala> dfb.registerTempTable("tbb")
scala> val join = spark.sql("select a from tba left join tbb on tba.a = tbb.b")
join: org.apache.spark.sql.DataFrame = [a: int]
scala> join.count
res44: Long = 10000000
scala> val plan = spark.sql("explain extended select a from tba left join tbb on tba.a = tbb.b")
plan: org.apache.spark.sql.DataFrame = [plan: string]
scala> println(s"${plan.first.getString(0)}")
== Parsed Logical Plan ==
'Project ['a]
+- 'Join LeftOuter, ('tba.a = 'tbb.b)
:- 'UnresolvedRelation [tba]
+- 'UnresolvedRelation [tbb]
== Analyzed Logical Plan ==
a: int
Project [a#78]
+- Join LeftOuter, (a#78 = b#85)
:- SubqueryAlias tba
: +- Project [value#75 AS a#78]
: +- SerializeFromObject [input[0, int, false] AS value#75]
: +- ExternalRDD [obj#74]
+- SubqueryAlias tbb
+- Project [value#82 AS b#85]
+- SerializeFromObject [input[0, int, false] AS value#82]
+- ExternalRDD [obj#81]
== Optimized Logical Plan ==
Project [a#78]
+- Join LeftOuter, (a#78 = b#85)
:- Project [value#75 AS a#78]
: +- SerializeFromObject [input[0, int, false] AS value#75]
: +- ExternalRDD [obj#74]
+- Project [value#82 AS b#85]
+- SerializeFromObject [input[0, int, false] AS value#82]
+- ExternalRDD [obj#81]
== Physical Plan ==
GpuColumnarToRow false
+- GpuProject [a#78]
+- GpuShuffledHashJoin [a#78], [b#85], LeftOuter, GpuBuildRight, false
:- GpuShuffleCoalesce 2147483647
: +- GpuColumnarExchange gpuhashpartitioning(a#78, 10), true, [id=#653]
: +- GpuProject [value#75 AS a#78]
: +- GpuRowToColumnar TargetSize(2147483647)
: +- *(1) SerializeFromObject [input[0, int, false] AS value#75]
: +- Scan[obj#74]
+- GpuCoalesceBatches RequireSingleBatch
+- GpuShuffleCoalesce 2147483647
+- GpuColumnarExchange gpuhashpartitioning(b#85, 10), true, [id=#660]
+- GpuProject [value#82 AS b#85]
+- GpuRowToColumnar TargetSize(2147483647)
+- *(2) SerializeFromObject [input[0, int, false] AS value#82]
+- Scan[obj#81]
As we can from the Physical Plan output above, Spark Rapids has
altered the physical query plan to use GPU accelerated operations.
This query plan output is also a good example of the Spark Rapids plugin design:
Rapids allows Spark to perform logical plan optimization as usual,
and applies the lower-level GPU optimizations to the resulting physical plan.
We can also make use of Spark’s Web UI to view the operation of Spark Rapids. The following screen shot shows the modifications that Spark Rapids has made to the query:
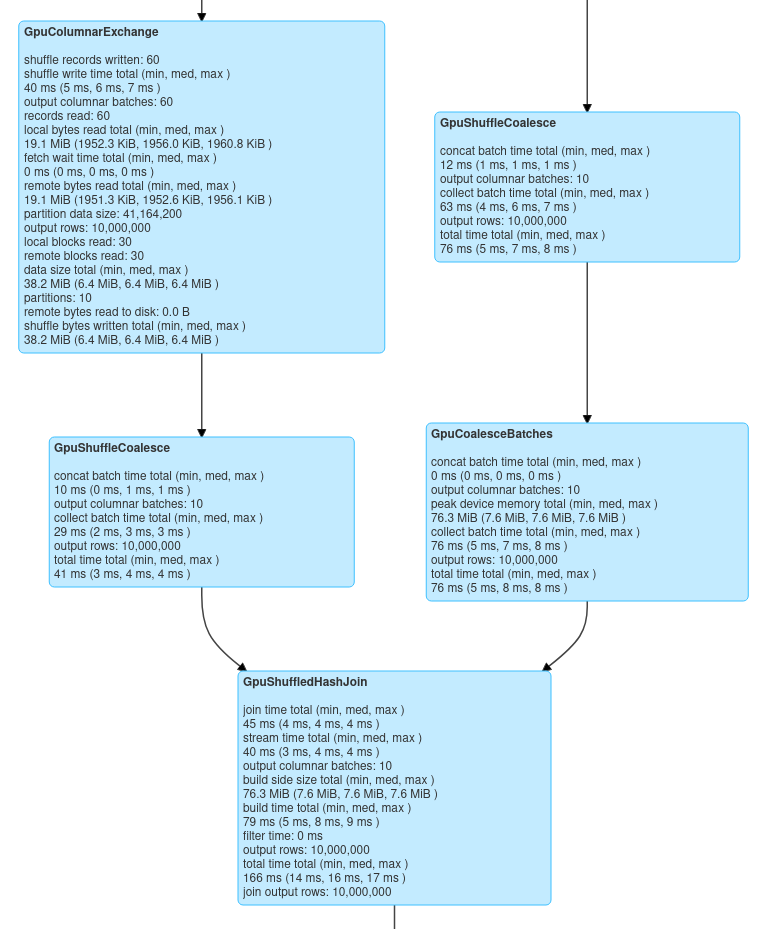
Benchmarking
The above test query ran in approximately 11 seconds using Spark Rapids.
We ran a corresponding spark-shell
configured without GPU support
and the test join ran in approximately 40 seconds,
and so Spark Rapids accelerated our test by ~4x in our hardware environment.